迭代器
提出迭代器概念的动机:
- 在软件构建过程中,集合对象内部结构常常变化各异。但对于这些集合对象,我们希望在不暴露其内部结构的同时,可以让外部客户代码透明地访问其中包含的元素;同时这种“透明遍历”也为“同一种算法在多种集合对象上进行操作”提供了可能。
GOF《设计模式》中迭代器模式的定义:
提供一种方法顺序访问一个聚合对象中的各个元素,而又不暴露(稳定)该对象的内部表示。
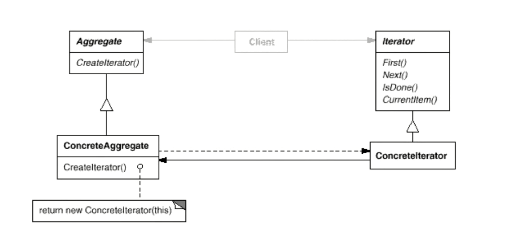
迭代器是一种检查容器内元素并遍历元素的数据类型。
每种容器类型都定义了自己的迭代器类型,如vector
1 | vector <int> in_vec(10,1); |
Iterator的作用

Algorithms看不见Containers,对其一无所知。所以它需要的一切信息都必须从Iterator获得,而Iterator(由Containers提供)必须能够回答Algorithms的所有提问,才能搭配Algorithms的所有操作。
Iterator必须能回答Algorithms关于Containers的iterator_category 、value_type、 difference_type、 reference、 pointer五种associated types。
举例:List(单向)迭代器简单实现
1 | template<typename T> |
从以上实现可以看出,为了完成一个针对List而设计的迭代器,无可避免的暴露了太多List的实现细节;在main()中为了制作begin和end两个迭代器,我们暴露了ListItem;在ListIter class中为了实现operator++的目的,我们暴露了ListItem的操作函数next()。
用面向对象实现迭代器
1 | //利用面向对象实现迭代器 |
萃取机
STL的核心思想就是:将数据容器和算法分开,彼此独立设计,最后再以一帖胶着剂将它们撮合在一起。
《C++标准库》有一句话说的很好,“iterator是一个抽象概念,任何东西,只要其行为像iterator,它就是iterator”。而不同的容器可能需要不同行进能力的iterator。
1 | template<typename T, typename Ref, typename Ptr> |
每个容器有各自的iterator,现实中C++的iterator设计过于繁琐,详解见 《C++标准库》,这里只是介绍下设计iterator中经典的思想trait技法;
迭代器获取对象的类型
利用function template的参数推导机制:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21template <typename I, typename T>
void fun_impl(I iter, T t)
{
T temp; //这样可以通过模板的参数推导,推导出T的类型
//...功能实现( func()函数的功能 )
}
template <typename I>
inline
void func(I iter)
{
//func对外的接口
func_impl(iter,*iter)
}
int main()
{
int i;
func(&i);
}
//这种类型推导的方式只能推导参数的类型,并不能推导返回值的类型声明内嵌类型
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20template <typename T>
struct MyIter{
typedef T value_type; //内嵌类型声明(取别名)
T* ptr;
MyIter(T* p = 0) : ptr(p){};
T& operator*() const {return *ptr;}
//...
}
template <typename I>
typename I::value_type func(I iter)
{return *iter;}
int main()
{
MyIter<int> iter(new int(8));
cout<<func(iter); //输出8(int类型)
}
//但是不是所有的迭代器都是结构体类型,如果是原生指针这种方式就不能实现了偏特化(Partial Specialization)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34//如果class template 拥有一个以上的template参数,我们可以针对其中某个(或数个,但非全部)tempalte参数进行特化.
template <typename T>
struct MyIter<T*>{ //偏特化版本,得到一个T*类型的原生指针
typedef T value_type; //内嵌类型声明(取别名)
T* ptr;
MyIter(T* p = 0) : ptr(p){};
T& operator*() const {return *ptr;}
//...
}
/*
//如果T的类型被const修饰如何?
//这就需要另外的特化版本
template <typename T>
struct MyIter<const T*>{ //偏特化版本,得到一个T*类型的原生指针
typedef T value_type; //内嵌类型声明(取别名)
T* ptr;
MyIter(T* p = 0) : ptr(p){};
T& operator*() const {return *ptr;}
//...
}
*/
template <typename I>
typename I::value_type func(I iter)
{return *iter;}
int main()
{
MyIter<int> iter(new int(8));
cout<<func(iter); //输出8(int类型)
}
traits
traits:如果I有自己的value_type,那么通过这个traits的作用,萃取出来的value_type就是I::value_type。简单的说traits是一个中间层,目的就是为了获得变量的类型。
下图说明了trait扮演的”特性萃取机”角色,萃取各个迭代器的类型。
这个traints机器必须有能力分别它所获得的iterator是class iterator T 或是 native pointer T.

最常用的迭代器类型有五种:value_type 、 difference_type、 pointer、 reference、 iterator_category .
1 | template<typename I> |
以上这种不带成员变量和成员函数的类可以作为基类给子类来进行继承,这种的类的继承类似于inline的作用。
value_type 是指迭代器所指对象的类型。
difference_type用来表示两个迭代器之间的距离,因此它也可以用来表示一个容器的最大容量。
reference_type,从”迭代器所指之物的内容是否允许改变”来看,迭代器分为两种:1.不允许改变”所指对象内容”称为constant iterators,例如const int* pic;2.允许改变“所指对象内容”,称为mutable iterators,例如:int* pi。
pointer_type,指向迭代器所指之物
iterator_category 迭代器的类型(移动性质)。input iterator 、output iterator 、forward iterator 、bidirectional iterator 、random access iterator。
总结
迭代抽象:访问一个聚合对象的内容而无需暴露它的内部表示.
迭代多态:为遍历不同的集合结构提供一个统一的接口,从而支持同样的算法在不同的集合结构上进行操作.
迭代器的健壮性考虑:遍历的同时更改迭代器所在的集合结构,会导致问题.